
ELI5: ZFS, RAID, Storage, etc.

I love ZFS, and you should too. It's a filesystem with built-in support for encryption, compression, deduplication, RAID, and a whole host of other features.
When I first encountered ZFS, it was as a result of working with TrueNAS and Proxmox systems. While I understood the basics, there were a few nagging questions no one seemed to be able to answer, and most guides & diagrams online were incomplete. I now have a much better understanding of ZFS, and in this guide I intend to walk you through absolutely everything you need to know.
This guide encompasses (almost) all of ZFS, and a few other related concepts and terminology in the simplest language possible. It is not intended to be perfectly technically accurate, but to give those who are confused (as I once was) a solid mental picture onto which they can begin to build via their own work and research. It is largely homelab focused, but a good amount of information is applicable to work/enterprise environments as well.
This guide is a work-in-progress. Some sections may be missing or incomplete.
How Does ZFS Work?
Like this:
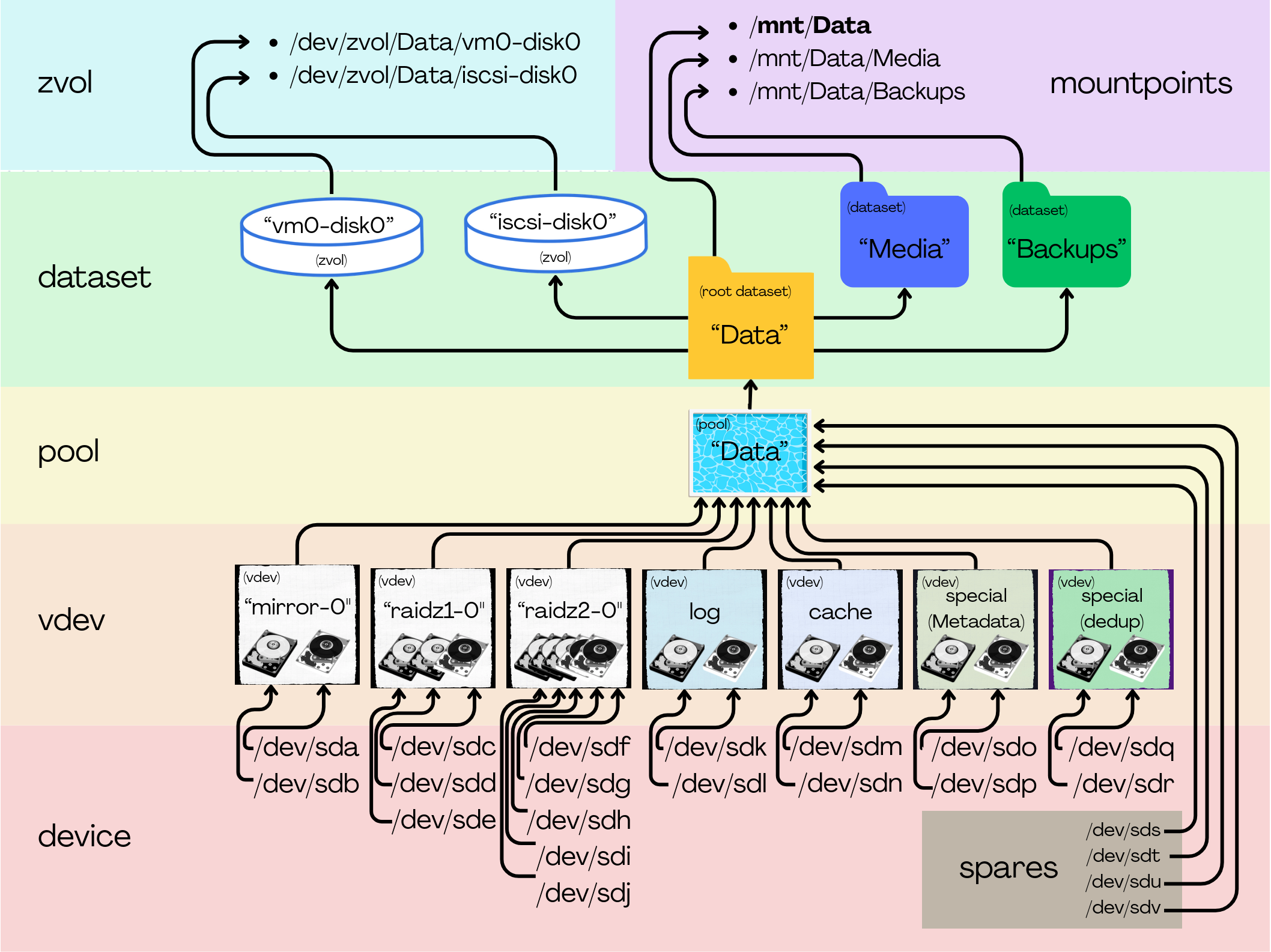
Let's start with some terminology:
ZFS Terms:
- device - A literal storage device/disk, like a hard drive or SSD.
- vdev - A virtual device made up of actual disks. For example, two disks can be mirrored (RAID1) in a single vdev, or three disks in a RAIDZ1(RAID5)
- pool - vdevs are combined into a pool. Data is generally split up and written/read across all the vdevs. There are special vdevs that behave a little different (We'll get to that later.)
- dataset - A data partition, sort of. When a pool is created, a root dataset is also created with the same name as the pool. Every other dataset is a child of this dataset, and inherits all the same options unless overridden. These are mounted like regular folders and you can treat them as such.
- zvol - A special kind of dataset that shows up as virtual hard disk in the form of
/dev/zvol/poolname/zvolname These can technically be formatted like any other disk, but generally you'll use these for something like iscsi or VM disks under Proxmox. - width - This is a term used to describe how many drives are in a vdev.
General Storage Terms:
- striped/striping - The process of splitting up data and writing parts to multiple places at once.
- metadata - Sort of like a map, that tells the system where all the data is located on disk.
- deduplication/dedup - The process of identifying identical chunks of data, and instead of storing multiple copies, keeping one copy and using pointers that point to it, thus saving space on disk.
- block - Files are automatically broken up, and the data is stored on the dataset in pieces called blocks.
- sector - Blocks are automatically broken up, and the data is stored on drives in pieces called sectors.
Let's talk about vdevs:
There are a bunch of different types of vdevs.
Data vdevs
- Stripe - Similar to RAID0
- Smushes together a bunch of drives into one.
- Can actually just be one drive.
- ANY drive failure results in total loss of all data.
- Mirror - Similar to RAID1
- A drive is coupled with one (or more) identical duplicates.
- Can withstand losing all but ONE drive.
- RAIDz1 - Similar to RAID5
- Data (and parity data) is striped across drives.
- Can withstand losing ONE disk.
- Typically used with 3 or more disks.)
- RAIDz2 - Similar to RAID6
- Data (and parity data) is striped across drives.
- Can withstand losing TWO disks.
- Typically used with 5 or more disks.
- RAIDz3 - Similar to RAID6
- Data (and parity data) is striped across drives
- Can withstand losing THREE disks.
- Typically used with 7 or more disks.
Fancypants vdevs
-
cache - Also known as L2ARC
- Helps with READ speeds
- Stores frequently accessed data automatically
- Failure doesn't hurt anything
- Typically single/stripe on SSD
-
log - Also known as SLOG
- Stores written data temporarily, then later migrates to data vdevs
- Usually mirrored on fast durable/enterprise SSD
- Failure may cause data loss (although now unlikely.)
-
metadata - A type of special vdev, stores just metadata for the pool.
- Increases read/write speed by taking over metadata duty from the data vdevs
- Can also optionally hold files/blocks below a certain size.
- Failure will cause complete data loss
- Typically a mirror on fast/durable SSDs
-
dedup - A type of special vdev, stores deduplication tables
- Increases read/write speed by taking over deduplication tables from the data vdevs
- Failure will cause complete data loss
- Only useful if you are using deduplication (and you probably aren't)
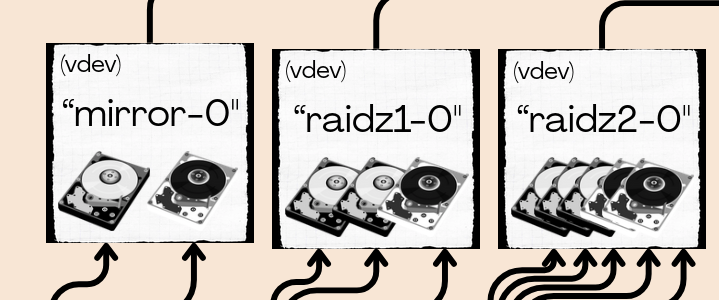
Each raid level applies to the disks within a vdev. When those vdevs are combined into a pool they are striped together automatically, similar to RAID0, although with more intelligent distribution. This sort of puts an end to the RAID0+1 vs RAID1+0 conversation.
This means redundancy only applies at the vdev level.
If any one vdev fails completely you will lose all the data in the pool, no matter what configuration you use.
How should I configure my drives?
This is a question that gets asked A LOT and the answer is, it depends.
There is a ton of confusion regarding this, because what is true at the vdev level is not automatically true at the pool level.
The pool level is the only thing that matters, really.
Let me show you what I mean.
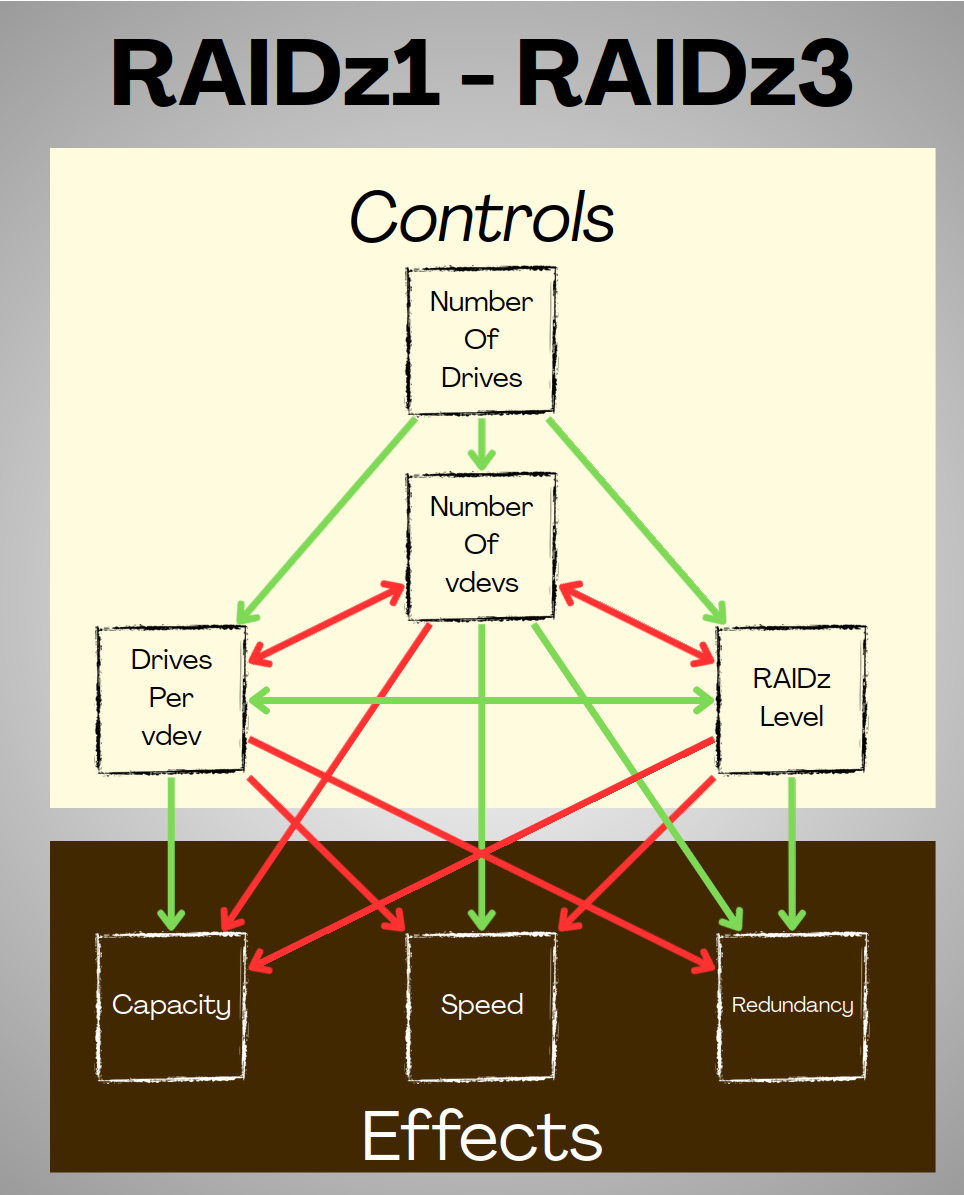
In a pool, Assuming we have a limited number of drives, and we want to make optimum use of them, we have three controls at our disposal:
- Drives per vdev
- Number of vdevs
- RAIDz level
Each has a relationship with the others.
- If we add more drives per vdev, we can't create as many vdevs.
- If we increase the number of vdevs, we have to have fewer drives per vdev.
- If we increase the RAIDz level, our minimum vdev width goes up, and we can create fewer vdevs.
Each Control affects the properties of the pool:
- Capacity
- Speed
- Redundancy
Mirrors and stripes are a little different...
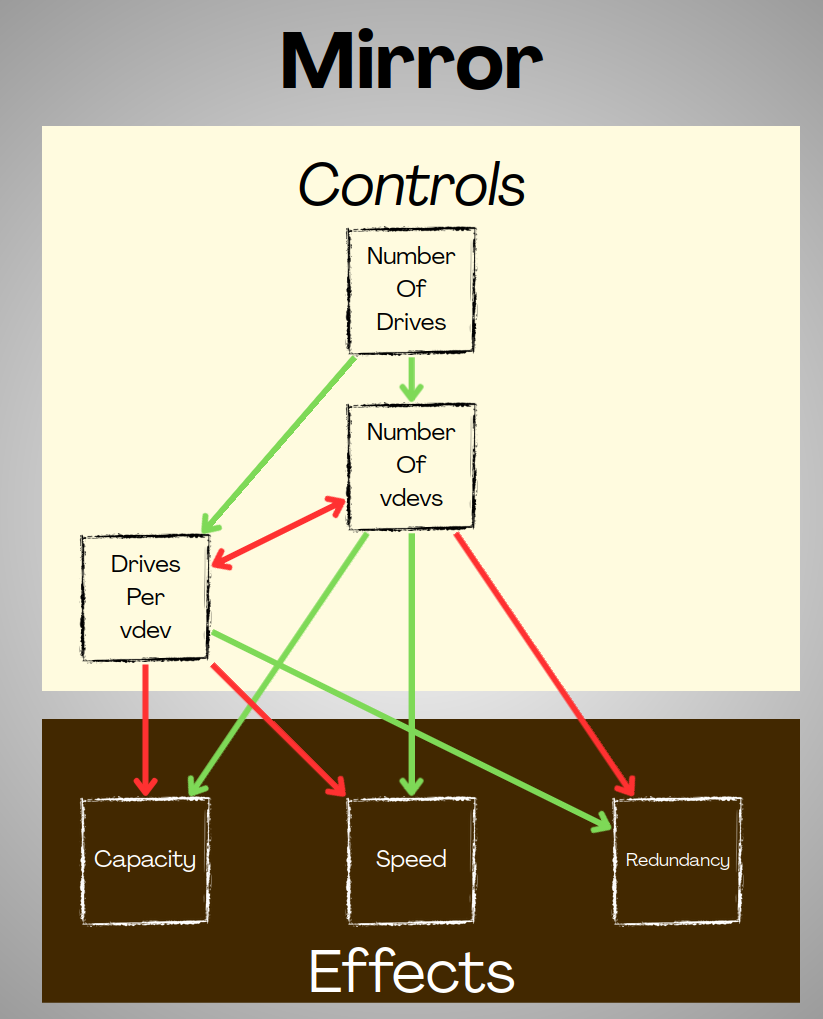
With mirrors, there are no RAIDz levels;
At the vdev level, wider mirror vdevs add read speed, but do not change write speed.
At the pool level, wider mirror vdevs create more redundancy, at the cost of capacity & speed, and vice-versa.
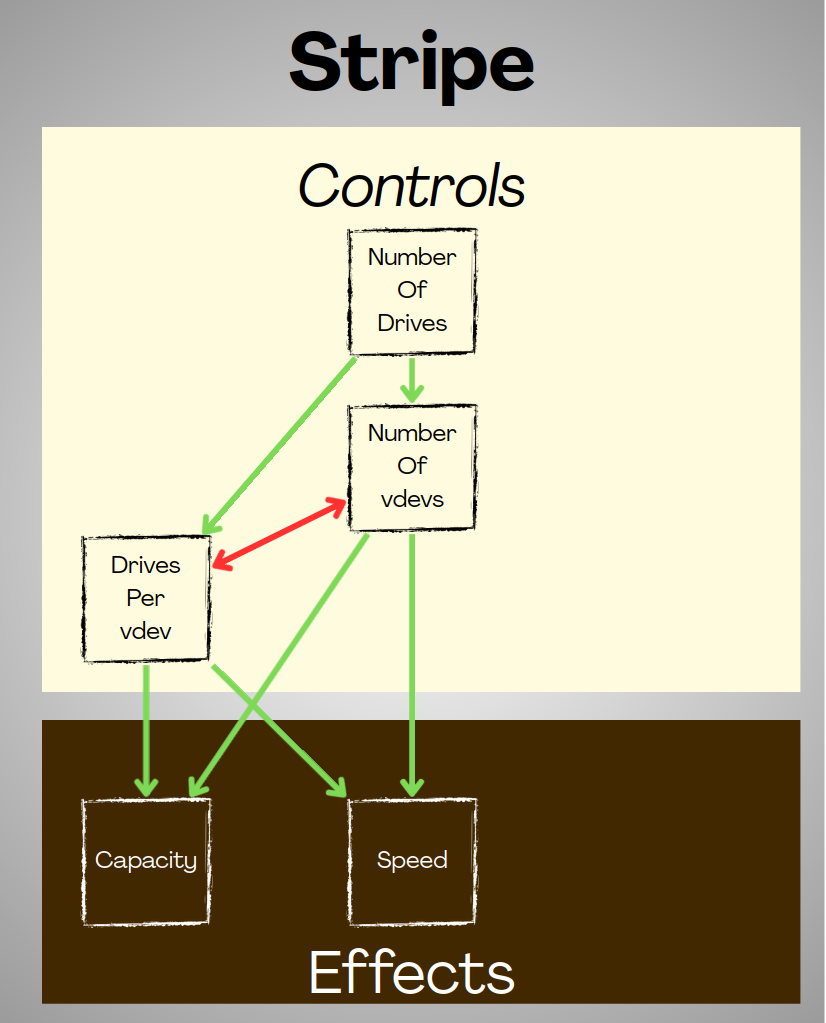
With Stripes, there is no redundancy, at all, period.
This also means your vdev width is mostly irrelevant.
In any configuration...
our limiting factor is always going to be the number of drives. If you have the money to go out and buy a bunch of drives, why are you even asking? Just do it! Fill your house with them! More drives will always make things better (assuming you have the hardware to connect them, and the money to pay for electricity.)
How do the controls affect things? How do I know what to prioritize? How now brown cow? Let's discuss.
All about CAPACITY
Please bear in mind, all of these calculations are approximate, as there are a few additional caveats like metadata. Generally though, capacity estimates are pretty accurate.
In a stripe vdev, effective capacity is
- (Single Drive Capacity) x (Number of Drives)
There is no parity data, so each drive you add just gets added to the vdev as additional storage.
In a RAIDz1, effective capacity is
- (Single Drive Capacity) * (Number of Drives - 1)
This is because we are only creating ONE parity copy of the data, and spreading it across all the drives.
If I have Three 1TB Drives in a RAIDz1 and I write 100MB of data to it, the system creates a copy for parity and it becomes 200MB of data.
If I have Four 1TB drives in a RAIDz1 and I write 100MB of data to it, the system still only creates one copy for parity, so it's still 200MB of data.
What if we add more drives?
* Going from 3 -> 4 1TB drives gives an extra 750GB of effective capacity.
* Going from 4 -> 5 1TB drives gives an extra 800GB of effective capacity.
* Going from 5 -> 6 1TB drives gives an extra 833GB of effective capacity.
In a RAIDz2, effective capacity is
- (Single Drive Capacity) * (Number of Drives - 2)
This is because we are creating TWO parity copies of the data, and spreading it across all the drives.
If I have Five 1TB Drives in a RAIDz2 and I write 100MB of data to it, the system creates two copies for parity and it becomes 300MB of data.
If I have Six 1TB drives in a RAIDz1 and I write 100MB of data to it, the system still only creates two copies for parity, so it's still 300MB of data.
What if we add more drives?
* Going from 5 -> 6 1TB drives gives an extra 666GB of effective capacity.
* Going from 6 -> 7 1TB drives gives an extra 714GB of effective capacity.
* Going from 7 -> 8 1TB drives gives an extra 750GB of effective capacity.
In a RAIDz3, effective capacity is
- (Single Drive Capacity) * (Number of Drives - 3)
This is because we are creating THREE parity copies of the data, and spreading it across all the drives.
If I have Seven 1TB Drives in a RAIDz3 and I write 100MB of data to it, the system creates THREE copies for parity and it becomes 400MB of data.
If I have Eight 1TB drives in a RAIDz1 and I write 100MB of data to it, the system still only creates two copies for parity, so it's still 400MB of data.
What if we add more drives?
* Going from 7 -> 8 1TB drives gives an extra 625GB of effective capacity.
* Going from 8 -> 9 1TB drives gives an extra 666GB of effective capacity.
* Going from 9 -> 10 1TB drives gives an extra 700GB of effective capacity.
In a mirror vdev, effective capacity is
- (Single Drive Capacity)
For each drive you add, you need another parity copy of the data. If I have two 1TB drives in a mirror, and I write 100MB of data to it, the system creates a copy for parity, so really I write 200MB of data. If I have a three way mirror, now it's 300MB. You get the idea, it cancels out.
What if we add more drives?
Adding more drives to a mirror vdev does not increase capacity, at all. It only adds more redundancy.
What does it all mean?
As far as capacity is concerned, adding drives to a mirror vdev accomplishes nothing.
Adding additional drives to a RAIDz vdev for additional capacity however, makes a lot of sense. The first drive you add will have the least effect on overall capacity, but each subsequent drive will add more and more storage per-drive (although it will taper off.)
That might make something like a RAIDz1 more tempting, and technically RAIDz1 is the most storage-efficient configuration while still having some redundancy.
A Stripe vdev is obviously the most efficient as there is zero parity data. If the data is not at all vital (like a cache or something) and you really need all the storage, it's not a bad choice.
All of this, however, is only looking at things on the scale of a single vdev... but we create multiple vdevs and combine them into a pool!
What's a pool look like?
Let's say we have 210x1TB disks to throw around.
We can create a pool with:
- Any number of Any-width Stripe vdevs for 210TB of capacity
- 70 3-drive RAIDz1 vdevs with 140TB of capacity
- 42 5-Drive RAIDz2 vdevs with 126TB of capacity
- 30 7-Drive RAIDz3 vdevs with 120TB of capacity
- 105 2-drive Mirrors with 105TB of capacity
Actually the rules for capacity hold true for the pool as well as the vdev. It might look like Mirrors suck for capacity, and they do, but they have some other unique benefits we'll get into in a bit.
All about SPEED.
How fast is a stripe vdev?
- Read = (Single Drive Speed) x (Number of Drives)
- Write = (Single Drive Speed) x (Number of Drives)
These boys are FAST. Data is split up and written to all the drives at once. There is no parity data to write, so RW speeds are just a sum of the speeds of all the drives.
What about a RAIDz1/RAIDz2/RAIDz3?
- Read = (Single Drive Speed) * (Number of Drives - RAIDz Level)
- Read = (Single Drive Speed) * (Number of Drives - RAIDz Level)
Since whatever drive you're using has a maximum throughput for read and write, adding a drive to a vdev theoretically adds one-drive-worth of speed to the vdev, but that only applies in a stripe (RAID0) scenario where you're just smushing the disks together. Once you throw redundancy in the mix, the written data is multiplied because the parity data has to be written as well, so your effective speed goes down.
There is a massive MASSIVE caveat here with RAIDz that we'll talk about shortly. Suffice it to say, you are very unlikely to see anything close to these speeds.
How about a mirror?
- Read = (Single Drive Speed) x (Number of Drives)
- Write = (Single Drive Speed)
These boys are FASTish... Write speed is just ok. If I create a mirror with two drives (which is the most common), and each drive has a 100MB/s read/write speed, that gives me 200MB/s bandwidth. If I write 1000MB of data to this vdev, it should take five seconds then right? No, writing that file takes 10 whole seconds, because I am writing one copy to the first drive, and another copy to the second. That 1000MB file is written twice and thus needs 2000MB of write. However when I read from the mirror, the speed is pretty much doubled. I can read at 200MB/s since the system is smart enough to pull different parts of the data I need from each drive at the same time and put them together. How cool is that?
What about a pool?
Within a pool, things are actually pretty straightforward.
Let's say we have 210 drives that can achieve 100MB/s and we want to create a single pool.
In our imaginary perfect world our performance looks like this:
- Any number of stripe vdevs with any number of disks = 21,000MB/s R/W
- 70 RAIDz1 3-disk vdevs = 14,000MB/s R/W
- 42 RAIDz2 5-disk vdevs = 12,600MB/s R/W
- 30 RAIDz3 7-disk vdevs = 12,000MB/s R/W
- 105 Mirror 2-disk vdevs = 21,000MB/s R, 10,500MB/s W
You may notice a pattern here, within a pool, more vdevs = more speed.
All about IOPS
Reading or writing a bunch of data sequentially, that is right next to eachother on disk, is always going to be faster than reading a ton of random small files, even if it's the same amount of data overall.
That's because what I have been referring to as "Disk speed" is actually just "Streaming Speed", but there's an additional factor here:
IOPS (Input/Output operations per second)
IOPS is the number of operations a disk can do in a second.
Every time the system has to stop writing data to read a file or switch from one stream of data to another, that has an IOPS cost.
Reading (or writing) one big old 10GB video file is a LOT faster than trying to find 2.5 Million 4KB text files, even though it may be the same amount of data.That's true on SSDs, but it's far FAR worse on ye olde spinning rust hard drives. That's because hard drives have a physical arm that must move around to read data off a hard drive.
To give a better idea of this, a Hard drive may have maximum IOPS in the triple-digit range, while an equivalent sized SSD may have anywhere from thousands to millions.
IOPS and RAIDz
IOPS ratings have a disproportionate effect on RAIDz configurations, because the data has to be broken up and spread across the drives by design (Unlike with mirrors) AND because there's more data due to parity (unlike stripes) AND the parity data is interlaced with the regular data (again by design).
When the RAIDz vdev receives a block of data to write, it breaks that block into smaller pieces called sectors, and sends them to each drive. It can't move on to the next block until every drive is finished writing.
Adding more drives to a vdev should increase your streaming speed, and under ideal conditions it will, but you'll always be limited by the number of IOPS of one single drive. (More specifically, the slowest drive.)
What this means is that sequential reads & writes, like reading one massive movie or something, will approach the big boy maximum streaming speed we calculated and won't hit the IOPS limit as they aren't hopping around much, if at all. However if you are doing any kind of random read/write, or bouncing around at all, you will likely rapidly approach that IOPS limit and your speed will drop, potentially by like... a lot, and quite suddenly.
So, a more realistic expectation for most workloads in a RAIDz vdev is closer to this:
- Read = (Single Drive Speed)
- Read = (Single Drive Speed)
Oof.
What about in a pool?
Let's go back to our hypothetical 210 drive pool.
As a reminder, these are our speed numbers for perfect sequential data:
- Any number of stripe vdevs with any number of disks = 21,000MB/s R/W
- 70 RAIDz1 3-disk vdevs = 14,000MB/s R/W
- 42 RAIDz2 5-disk vdevs = 12,600MB/s R/W
- 30 RAIDz3 7-disk vdevs = 12,000MB/s R/W
- 105 Mirror 2-disk vdevs = 21,000MB/s R, 10,500MB/s W
A more realistic expectation looks like this:
- Any number of stripe vdevs with any number of disks = 21,000MB/s R/W
- 70 RAIDz1 3-disk vdevs = 7,000MB/s R/W
- 42 RAIDz2 5-disk vdevs = 4,200MB/s R/W
- 30 RAIDz3 7-disk vdevs = 3,000MB/s R/W
- 105 Mirror 2-disk vdevs = 21,000MB/s R, 10,500MB/s W
So due to RAIDz IOPS limitations, real-world performance will vary somewhere in the following windows:
- Stripe = 0%
- RAIDz1 = 50%
- RAIDz2 = 66.6%
- RAIDz3 = 75%
- Mirror = 0%
In conclusion:
The things that work really well to overcome the speed limitations of RAIDz are to:
- Use a lower RAIDz level.
- Use more vdevs.
- Use fewer drives per vdev.
- Use drives with higher IOPS.
All about redundancy
I am making up an arbitrary metric to give you an idea of safety based on parity that I will call a "Safety Score". I divide the amount of parity by the total number of disks.
These numbers are all theoretical, but they give a pretty good ballpark. There are some additional factors to consider, and I'll discuss those shortly, but this will give you a good idea of relative safety.
Stripe vdevs
Safety Score: 0 disk parity (Always) / 1 disks (minimum) = 0% or less
The least safe is a stripe, which actually starts at 0% and goes down as you add more drives, (and breaks my made up metric.)
As we add additional drives:
1 Drives -> 2 Drives = Failure 100% MORE likely
2 Drives -> 3 Drives = Failure 50% MORE likely
3 Drives -> 4 Drives = Failure 33% MORE likely
RAIDZ1 vdevs
Safety Score: 1 disk parity (Always) / 3 disks (minimum) = 33% or less
Can lose precisely ONE drive without the vdev failing.
As we add additional drives:
3 Drives -> 4 Drives = Failure 33% MORE likely
4 Drives -> 5 Drives = Failure 25% MORE likely
5 Drives -> 6 Drives = Failure 20% MORE likely
RAIDZ2 vdevs
Safety Score: 2 disk parity (Always) / 5 disks (minimum) = 40% or less
Can lose precisely TWO drives without the vdev failing.
As we add additional drives:
5 Drives -> 6 Drives = Failure 20% MORE likely
6 Drives -> 7 Drives = Failure 17% MORE likely
7 Drives -> 8 Drives = Failure 14% MORE likely
RAIDZ3 vdevs
Safety Score: RAIDZ3 - 3 disk parity (Always) / 7 disks (minimum) = 42.8% or less
Can lose precisely THREE drives without the vdev failing.
As we add additional drives:
7 Drives -> 8 Drives = Failure 14% MORE likely
8 Drives -> 9 Drives = Failure 12.5% MORE likely
9 Drives -> 10 Drives = Failure 11% MORE likely
Mirror vdevs
Safety Score: Mirror - 1 disk parity (Minimum) / 2 disks (minimum) = 50% or more
Can lose precisely (Number of drives - 1) drives without the vdev failing.
As we add drives:
2 Drives -> 3 Drives = Failure 50% LESS likely
3 Drives -> 4 Drives = Failure 33% LESS likely
4 Drives -> 5 Drives = Failure 25% LESS likely
WHAT DOES IT MEAN????
- Stripes are dangerous, and since any one drive failing takes all the data with it, they get more dangerous the more drives you add.
- All RAIDz levels are not as safe as mirrors, but safer than Stripes. Like Stripes, they become less safe as you add more drives.
- Higher RAIDz levels are safer than lower ones.
- Mirrors are the safest, right off the bat, and unlike every other configuration they actually become more safe the more drives you add.
All about backups
RAID is not a backup... is it?
This has been discussed to death, but generally not in a productive or balanced way. I'd like to change that.
Many will say "RAID is not a backup" and they are technically correct
...yet in practice pretty much everyone who uses RAID treats it... kind of like a backup.
Both views are correct, kind of.
RAID's primary purpose is to ensure availability, meaning if a drive fails you can still access all the data in your array. This is extremely important in an enterprise environment where an outage could cost millions of dollars. You can wait until night, or the weekend when usage is low, then swap in a good drive and begin resilvering.
In a home environment, that's generally not the case. While the data we store may be important, it's not really mission-critical that it be available 24/7. If a drive fails in the middle of the day, most of us would just pop a new one in and begin resilvering immediately to get it over with. But in practice RAID does serve the purpose of a backup, in that there is at least one redundant copy of the data that is available if something fails.
If SOMETHING fails...
If a drive fails, RAID acts like a perfectly good backup.
If an entire array gets fried from a power spike or a brownout, or if your cat sneaks in and pees on your DAS, RAID will not do you much good.
So in my humble opinion, RAID IS a backup, but generally it's not good enough to be anyone's ONLY backup.
Do I need RAID?
In an enterprise environment, or a business, or any professional setting, you should be using RAID,
AND at least one on-site backup,
AND at least one off-site backup,
bare minimum, no question.
In a home environment, it depends.
I have a mix of crap on my home server. There are important documents, projects, precious photos. There's also a lot of music and movies and other media that doesn't really matter and takes up a lot of space.
I'm probably safe backing up the important stuff into the cloud (Maybe ProtonDrive via rClone) and using stripe vdevs. But if a drive were to fail, instead of being able to pop a new drive in, run a command and walk away, I now have to pop a new drive in, create a new pool, download all my data from the cloud, and then re...acquire... all my media again. It'd be a big pain.
While there are many other things that could go wrong with my data, the most likely is a single drive failure. If my server dies, I can build another one. If my DAS dies, since I'm using ZFS and not an arbitrary RAID enclosure, I can buy another one and import the pool.
Then again, I don't NEED 24TB of space. Not even close. I could absolutely get away with 12TB of space, and since it may save me a headache in the future, and it makes my data that much safer, and it doesn't cost anything, I went with mirrors.
Ultimately the choice is up to you, but if there is one takeaway here it's this:
Do not use RAID as your only backup of important data.
Then what are my options for backups?
You do have a number of choices, and you should use as many as possible.
I'll talk more about how to decide what to backup and where in the "What should I do?" section.
What about snapshots?
All about Replication
All about Snapshots
All about resilvering
If a disk fails in either a mirror or a RAIDz vdev, you can swap in a new drive as a replacement. All the data the new drive needs will be copied over from the other drives in the vdev. This process is called resilvering.
On a stripe vdev
There is no such thing as resilvering. If you lose a drive, your data is gone, you are boned, go directly to jail, do not pass go, do not collect $200.
On a mirror vdev
This process is very quick. All the data for the new disk exists on the other disk(s) in the mirror. All the system has to do is make a 1-to-1 copy.
- The more data on the vdev, the longer it will take.
- Wider vdevs have no effect, as you're limited by the write speed of the replacement drive (which is always going to be less than the read speed of all the other drives combined.
On a RAIDz vdev
Well, the parity data for RAIDz is peppered all over every single other disk in the vdev. If you don't use the pool at all while it's resilvering, even just to read things, this can be OK but it's still going to take WAY longer than resilvering a mirror, without question.
- The higher the RAIDz level, the longer it will take.
- The wider the vdev, the longer it will take.
- The more data on the vdev, the longer it will take.
There's also a hidden danger here.
Drives are more likely to fail the more they are used.
It's not uncommon for another drive to fail during resilvering, especially if they all came from the same batch.
It's much less likely with a mirror, since the process is faster and there's not really any jumping around going on. It pretty much just hoovers up the data from one drive and drops it on the other.
When resilvering a RAIDz, the process of reading all the data spread out over the other drives is very I/O intensive.
If another drive failure happens while resilvering a RAIDz1, you're screwed. If it happens on a RAIDz2 or RAIDz3 you have a chance to recover still, assuming more drives don't fail, and even that does happen on occasion.
All about Encryption (at rest)
Almost all the data you transfer over the internet is encrypted, at least until it arrives at it's destination. The same cannot be said for data-at-rest.
You should be encypting your data at rest.
If someone acquires your drives somehow (which happens more often than you might think), you don't have to worry that they'll be able to dig around in your files.
Furthermore, if you set things up correctly, even if they acquire the entire machine, they still won't have access to much of anything on it.
MacOS, Android, and iOS all have their own built in encryption mechanisms.
On Windows systems Bitlocker works quite effectively, although Microsoft is sent a copy of your recovery key, so if you're afraid of the government (and you probably should be) Veracrypt may be a better option.
On linux, we generally have to use LUKS (Linux Unified Key Setup)
First we format a disk with LUKS, then we unlock it (with either a keyfile or password) then we mount it, then we format THAT with EXT4 or whatever filesystem we use. Most Linux OS support system drive encryption as an option in the installer, but once it's installed it's a real pain to add encryption on later.
ZFS however has it's own built-in native encryption mechanism, and it's fantastic. ZFS encryption is applied in the middle-of-the-sandwich so to speak, at the dataset level. Before decryption, ZFS needs to be able to see what datasets (and zvols) there are, as well as a few other properties like size and name, in order to unlock and mount them correctly. As a result, those things can be viewed by a bad guy as well. Fortunately for us, unless you're naming your datasets after your favorite API keys or something, that's probably a non-issue. Technically this does make LUKS slightly safer though, as LUKS exists at a lower level than ZFS encryption and doesn't reveal partition names or sizes.
Another reason ZFS encryption is applied at the dataset level has to do with compression. Encrypted data is scrambled, and is thus pretty much impossible to compress. For ZFS compression to work with encryption, the data has to be compressed first. With encryption at the dataset level and not at the filesystem level, this works out perfectly.
What about performance?
There is a performance penalty for encryption of course, as the system has to do all the number crunching and rearranging of data to convert between encrypted and unencrypted data on-the-fly.
With ZFS, in the past, this performance hit could be pretty significant. (Some were recommending using ZFS on top of LUKS as it was actually faster!)
Things have improved pretty drastically over the past few years, and OpenZFS (The open-source implementation of ZFS) is still constantly receiving heavy work from developers and improving quickly.
As of right now, unless you have a very weak, old CPU, you're unlikely to even notice the difference.
All about deduplication
So, ZFS deduplication is a crazy controversial topic.
Mostly because no one actually knows what they're talking about, and they blindly parrot the common knowledge some redditor regurgitated from someone else, and so on, ad infinitum. Actually that might be the entire internet in general... Actually that might be what I am doing right now...
In any case, ZFS Deduplication used to be god awful, to the point where there was absolutely no point in using it for pretty much anyone, and it would tank your performance. Now, not so much, but it's still not that useful for most people.
First let's talk about hashes for a second. A hash is an algorithm that takes in some data and spits out a string, like this:
37786bc08e037c54510745ffdb39a935
This is an MD5 hash. Because of the way the algorithm is written, it's somewhere between extremelDDT ZAPy unlikely and impossible that two pieces of data will ever have the same hash.
If we want to check whether or not two blocks of data are identical, instead of comparing two big old blocks of data bit-by-bit (which would take ages), we can calculate the hash value for both and compare them.
Side note: You may hear the terms checksum and hash used interchangeably; For the most part, they are interchangeable and largely use the same algorithms. The main difference is that Checksums are primarily used to make sure a piece of data hasn't been corrupted or altered, while a hash is used to compare a piece of data to another piece of data.
The way deduplication works in ZFS is, in the simplest way possible, when a block of data comes in, the system calculates a hash of that block and stores the hash in a table called the DDT (Deduplication Table). When another block comes in, it calculates the hash for it, and then quickly compares the hash to all the other hashes in the table. Since the hashes are pretty small, this is a pretty quick process (Orders of magnitude faster than comparing the data bit-by-bit.) If it finds a match, rather than wasting space writing the same data again, it creates a little link to the existing data in the DDT.
The cleverer...er of you may already know what I'm about to say.
This is slow as balls.
When writing a data block, the system has to:
- Receive the block
- Compress the block
- Calculate a hash of the block
- Compare the hash to the hash of every other block in the dataset
- Write the block, or write a link to the DDT
When trying to read a file from a dataset, if a deduplicated block is encountered, the drives have to bounce all the way back to that other block that was written 6 months ago instead of continuing to read in a nice clean stream. Likewise, deleting files is a painful process.
The DDT gets hit HARD when using deduplication, and by default it's stored on the same dataset as the rest of the data!
All of this combined means a TON of extra IOPS. Using Deduplication on a set of spinning disks in a RAIDz configuration is a recipe for dial-up level speeds.
...Or is it?
Not so long ago, OpenZFS 2.3.0 was released, with a ton of updates specifically targeting improving deduplication performance, namely:
- DDT LOG - Hashes are stored in a log, sorted, then flushed to disk in batches instead of in random order as they arrive. Fewer write operations, and easier searching of hashes.
- Prefetch - Entire DDT is loaded into RAM at boot.
- Quota - Set a limit for the size on-disk of the DDT before pruning kicks in. Blocks additions to the table until there is more room.
- Pruning - Automatically clean up the DDT. If a block has existed for a very long time and yet has no duplicate data, it's probably safe to assume it never will. Those entries are deleted.
We also have the option of creating a special dedup vdev, specifically to hold the DDT. Typically this would be a mirror on two or more very fast SSDs (since losing the DDT means losing the entire pool, not just the deduplicated datasets... yikes.) and takes a ton of IOPs off the data vdevs.
So deduplication is good now, right?
Not really, no. It's way, way faster now, but it's still useless the vast majority of the time.
In order for a block to be deduplicated, it must be exactly identical to another block. How often does that happen in a big pile of random data? Basically never.
Unless you are writing large volumes of data that you are absolutely certain is mostly identical (for example, daily backups of VMs) you're extremely unlikely to gain anything from deduplication.
I tested this myself with a random mix of files from work, several hundred GB in size, and I got a deduplication ratio of 1.02x. So a 2% savings in space, with a pretty sizeable (although no longer catastrophic) reduction in performance.
All about compression
Another amazing feature of ZFS is called Compression. This is the act of making data take up less space on disk.
Very briefly, in order to avoid any confusion, there are two categories of compression.
- Lossless - Data that is compressed and then uncompressed is EXACTLY the same as it was before.
- Lossy - Data that is compressed loses some accuracy/quality in the name of saving space.
To give a really, really simple example of compression, imagine I have this message I really need to tell you about:
0000000000000000000000000000000000000000000000000000000000000000
If you and I are speaking in conversation, is it easier for me to say "ZEROZEROZEROZERO..." sixty-four times, or for me to say "Sixty-four zeroes."
The answer is obvious. The same is true of computers, although at a much, MUCH more complex scale. At their simplest, compression algorithms seek out patterns and create shortcuts.
What about lossy compression? That might look more like this:
0000000000000000000000000000000000000100000000000000000000000000
There's a sneaky little one in there, but I know that skipping that one isn't going to break anything, so I just say "Sixty-Four Zeroes" anyway.
An algorithm will know what will or will not break the data it's designed for, so in this case, maybe that little dark brown spot in the corner of the image is a little more black, or a little less round. To the human eye, it still pretty much looks like the same picture. That's lossy compression.
Some data, like text files & documents, tend to have a ton of empty space and repeating patterns, and they compress very well.
Other data, like video/audio/image files, have already been compressed to a stupid level by an algorithm specifically designed for that type of file, and there's no way it's going to get much smaller unless some genius creates a new algorithm for that specific filetype.
ZFS compression is, of course, lossless. That means if you store a JPG on ZFS, then move it somewhere else, it will not lose any quality. That is technically impossible. Do not @ me. Glad we got that out of the way.
ZFS will report how efficiently it's able to compress data using a metric called "Compression Ratio", a number starting at 1.00 (Meaning no compression) and increasing from there (2.00 meaning the data takes up half the space.) For example, The ratios on the datasets on my data server at work range from 1.00 to 1.63. This is a little confusing at first, personally I'd prefer the number represented the size of the compressed data instead (So data compressed to half the size would be .50 instead of 2.00) but alas, we must math on occasion, mustn't we?
ZFS has a ton of options for compression algorithms, but the default (LZ4) is so good it ends up having some very surprising effects.
LZ4 is a general-purpose compression algorithm, as are all the algorithms ZFS supports. That means it is designed to be pretty good at compressing whatever you throw at it. Even so, in practice the different algorithms tend to vary, sometimes by quite a bit, as far as how effective their compression is with certain types of data and how much CPU/RAM they have to eat to get there. There are other algorithms that may provide better compression ratios for certain types of data, but it's generally at the cost of a good chunk of resource utilization and may slow down transfer speeds. ZFS is an excellent happy-medium goldilocks algorithm with no real downsides for the vast majority of applications.
LZ4 will begin compressing some data, and upon realizing the data doesn't compress very well, it will give up and write the data as-is (A feature called "early abort") instead of wasting a bunch of CPU cycles trying to squish a rock.
When data IS compressible, LZ4 usually manages to compress the crap out of it VERY quickly while using VERY little additional resources. In fact, in almost all cases, reading and writing data on a dataset with LZ4 compression enabled is actually FASTER than working with uncompressed data, because once the data is compressed the data gets smaller and there's less data to move around. Couple that with the fact that CPU cycles are cheap, and the algorithm is really well written, and there's almost no reason not to use LZ4 compression.
Compression is enabled at the dataset level!
Not the pool level. That means you can have a bunch of datasets, all with different compression algorithms enabled within a single pool.
That makes testing which one works for your purposes pretty easy; Create a few datasets, set the algorithms, grab a representative sample of your data, copy it to each of the datasets, check the ratios. Done.
This also means, if you need the space, and happen to have a lot of data that compresses really well with the ZSTD-19 algorithm, you can place those files on their own dataset without slowing down everything else.
All about Caching
So a cache is, in essence,
a bit of faster storage used to temporarily hold data while it is processed, or transferred to/from other storage. Since data tends to be transferred in fits & spurts, this helps to even things out and speed things up.
Fast memory is expensive. The faster the memory, the more expensive it is. The fastest memory is volatile, meaning as soon as power is removed all the data is gone. Non-volatile memory retains data when power is removed, but it is much slower.
You can have layers of caching, where a small amount of extremely fast memory is served by a larger amount of very fast memory, which is served by an even larger amount of fast memory, you get the idea. This is more-or-less how your CPU works (L1,L2, & L3 cache respectively.) One of the duties of RAM is to act as a cache between your CPU and storage drives.
Your storage drives likely have their own small cache as well, though many cheaper SSDs have no cache at all (You may hear these called DRAM-less SSDs). This helps not only to speed up I/O, but to help prevent wear-and-tear on the drive, as many data operations can be very small and repetitive; DRAM doesn't ever wear out, but the FLASH memory in your SSD does.
All of this is to say, caching is important and almost no modern tech would work without it.
ZFS caching is pretty cool
ZFS uses your RAM as a cache for reading and writing data from your ZFS pool(s). This is referred to as the ARC (AdaptiveZIL Replacement Cache)
By default it will use up to 50% of your RAM, although you can change that by editing a config file.
Read Caching:
It will intelligently hold data it thinks you'll need soon, so that when you go to read it, you read at RAM speeds instead of drive speeds.
Not only is the streaming speed of RAM much higher than even the best SSDs (often 10x or more), but the time it takes to access data randomly strewn about is an order of magnitude higher at least; That's what RAM is pretty much designed for.
You can add a special vdev called, funny enough, "cache" (aka L2ARC... get it? Layer 2 ARC?) which will act as a READ cache in between your pool and your ARC. Since RAM is so much faster than even the fastest SSDs, it's generally suggested to add as much RAM as you can before even considering an L2ARC, and even then it's only really useful if your ARC is filling up regularly.
Write Caching:
Writes are a bit more complicated.
There are technically two types of writes. (These don't just apply to ZFS.) They are usually specified by the system sending the data over, but they can be overridden. After the data is received, how the system responds depends on the type of write requested:
- Asynchronous writes - "Let me know as soon as you receive the data."
- Default write type
- Faster
- More dangerous
When an Asynchronous write comes in, ZFS will cache it in RAM. It will immediately respond to the request with a confirmation. Every 5 seconds it will dump all the cached asynchronous writes to the dataset. Since RAM is volatile, if the system fails (like in a power outage) before the cache is flushed, we may end up in a state where the sender thinks the data was written, but it never actually was.
- Synchronous writes - "Let me know as soon as the data is safely written to storage."
- Less common
- Slower
- Safer
When a Synchronous write comes in, ZFS caches the data in RAM in what's called the ZIL (ZFS Intent Log), but it doesn't respond to the request until after it dumps the data to disk.
If the system fails before the data is written to disk, the sender knows the data was never successfully written as it never got a confirmation, and it can (hopefully) compensate accordingly.
Wait... isn't there a cache built-in to the drives as well? What if the power goes out while the data's in THAT cache?
Great question! In that scenario, as far as ZFS is concerned, the data has been written and confirmation has been sent. Drive caches are generally very small (a few MB) so you will likely lose, at most, a few seconds data. Depending on what the system was writing, could mean catastrophic system failure, or it could mean the loss of one of your cat GIFs, or nothing at all. For those of you old enough to have had a family desktop PC, this is why your parents warned you not to unplug it while it was running. There is something called PLP that can help mitigate this, but we'll get to that in the Drives section.
There's another special vdev called "log" (aka ZIL SLOG) that does the same thing as the L2ARC, but for synchronous write. When a synchronous write comes in, ZFS stores it in RAM, then dumps it to the SLOG, then reports the write as complete. Later on, as determined by ZFS, the data in the SLOG is written to the pool.
All about recordsize (and records, and blocks, and sectors)
...and a few related things.
I mentioned this near the beginning but on a dataset, when you store files, those files are broken up into blocks.
This is true for pretty much every filesystem, but part of what makes ZFS unique is that, at least for regular datasets (not zvols) this setting is an upper limit, not a requirement.
In most filesystems, writing a 4KB text file to a filesystem with a 128KB recordsize would take up 128KB of space. The rest of the block would be padded, in order to keep some semblance of sanity & order in the way the data is laid out. This is one form of what's known as "write amplification" where more data is written than should be, but it's difficult to avoid in a world where not all our files are not exactly clean powers-of-two like 4KB or 1MB or what have you. Additionally, since the system is only capable of reading data block-by-block, to open that 4KB text file you now have to read an entire 128KB block of mostly nothing. Arguably, this is a form of "Read Amplification" but almost no one uses that term.
To help overcome this, ZFS uses dynamic blocksize. The recordsize serves as a maximum limit for any block. It will shrink the block to fit a file to any power of 2, as low as 512 bytes, and as high as whatever recordsize limit you've applied to that dataset (128KB by default). When you have tons of small files, this can save a lot of space, and speed up read and write speeds by quite a lot.
There are a few caveats: A single file can only use one blocksize. If you have a file that is 129KB in size, and a 128KB recordsize, it will be split into one 128KB block full of data, and another 128KB block with 127KB of padding. Nevertheless, this is still much more efficient in the real-world than having a static recordsize.
Recordsize just sets the upper limit for Blocksize. Blocksize is what matters.
What does blocksize do?
Blocksize has an effect on just about EVERYTHING, including streaming speed, IOPS, storage capacity, deduplication, compression, even encryption. Let's get into it.
How does Blocksize affect Storage Capacity?
The data explaining where blocks are located and what files they represent is stored in the "metadata". Every single block has an entry in the metadata. The smaller the blocks, the more blocks, the more entries.
Depending on the what kind of files are stored, changing recordsize may increase or decrease the amount of storage used. If we had a ton of 513KB files and a recordsize of 512KB or more, we'd waste close to 50% of our space on padding alone. As a general rule though, for random data, making your recordsize bigger does save a bit of disk space. But that's a moot point when we factor in compression!
How does Blocksize affect Compression?
Well, you know all that wasted padding space we have because we lost our minds and set our recordsize to 16M? Compression is exceptionally good at spotting a big fat stack of zeros and getting rid of it. With compression enabled, the issues of larger blocksizes become basically a non-issue as far as disk space goes.
Furthermore, since compression works one-block-at-a-time, if you give it bigger blocks, it has more data to search through to find places to save space.
This potentially means slightly higher latency and slightly lower speed, but it also means higher compression ratios, saving more disk space.
How does Blocksize affect IOPS?
Smaller blocks = more blocks. More blocks = More IOPS.
How does Blocksize affect Streaming Speed?
Higher blocksize means faster speeds! (Up to a point.)
Since the system grabs one block at a time, the bigger the block, the more data we can grab at once.
More specifically:
Let's also say the average seek time on a spinning disk hard drive, meaning the time it takes for the reader arm to move over to a different place and read a block, is about 8 milliseconds.
Let's say that the average hard drive takes about 1 millisecond to read 128KB of data (the default ZFS recordsize).
It's not all that efficient to have your hard drive spend 8ms to read 1ms of data. What we really want is for those numbers to be at least equal, so the drives in the pool can sort of take turns and keep the stream nice and steady. A typical hard drive takes about 8ms to read 1M of data (128K x 8ms = 1024K = 1M) thus 1M is a good number for streaming speed.
There is a point of diminishing returns however. In practice it seems to be at about the 1MB point (You can set recordsize up to 16MB)
Beyond 1MB things tend to flatten out, as there's already a pretty good stream of data going. At really high sizes like 16M it may even start to slow down a bit.
With SSDs this all goes out the window. There is still a seek time with SSDs and you still have to worry about IOPS (Especially in a RAIDz) but the issue is much less obvious. Higher recordsizes may help with speed but may cause write amplification, especially if theres a database or VM running on the dataset.
Setting higher blocksizes may force ZFS to keep data less fragmented and more contiguous as well, since it's harder to find a place to shove a 1MB piece of data than it is to find several small holes to shove a few 128KB pieces in. As the disk fills, this will slow down read speeds, but increase write speeds, at least a little bit.
How does Blocksize affect deduplication?
This one is complicated. Since an entire block has to match to be deduplicated, theoretically having smaller blocks should mean better deduplication and less storage used (as you'd think a bigger block is more likely to have a single small change that makes it not match any more.)
In practice, any disk space gains from reducing blocksize in conjunction with deduplication are negated by the following:
- Metadata increases in size
- DDT increases in size
Additionally, often data you'd want to store deduplicated (like VM backups) will be largely the same, with a few big chunks that change with each iteration.
If you are backing up a database (or a VM that contains a database) your best bet is to use the same recordsize the DB uses for live storage (usually 64K or 16K). Lowering it likely won't save you anything, since all modified data in the live system would have been changed in recordsize blocks.
Furthermore, since every block processed by deduplication has to have a hash computed, AND that hash table (DDT) is stored in RAM, and the DDT has to be sync'd between RAM and your pool, smalled blocksizes will result in more CPU usage, more RAM usage, and will slow down your I/O, although to what degree there are too many variables to calculate.
What about zvols?
Since zvols are basically a fake hard disk that may or may not have another filesystem on top of it, ZFS can't actually see what files (if any) are on a zvol. Thus a zvol gets assigned a "volblocksize" which behaves kinda like a recordsize on any other filesystem. The default volblocksize value is 16KB
What about sectors?
You may also hear this referred to occasionally as physical block size.
Sectors are how physical disks break up and store data.
Sector size is determined by the drive manufacturer and often cannot be changed (but not always).
There are only a few common sector sizes you're likely to encounter:
- 512n (512B Native) - Older hard drives use 512 Byte sectors.
- 520B - Some older enterprise stuff uses 520B sectors, with an extra 8B for things like RAID data.
- 520B drives are kind of proprietary and can't be read by most OS (including linux)
- 4Kn (4KB Native) - Newer hard drives & SSDs use 4k sectors (8 times the size).
- There are still a number of things floating around that do not work with 4k sectors, although now those are exceedingly rare.
- 512e (512B Emulated) - There are some drives that have 4k sectors, but present themselves to the system as having 512B sectors (Known as 512e, for emulated).This is largely for backwards compatibility.
- Because 512e drives use 4k sectors on the hardware level, they perform pretty much identically to drives that are properly 4kn.
- 8Kn (8KB Native) - Supposedly there are a few SSDs floating around that use 8KB recordsize, but I have yet to come across them in the wild, and info on them is scarce.
- There are a few other sector sizes floating out there, but they are mostly proprietary and you're unlikely to encounter them.
You can sometimes use a process called low-level formatting to change the sector size of a disk (Especially useful for changing 520B drives to 512n so you can actually use them.) but it depends on the model and manufacturer, etc. I will elaborate on this later.
Why the change?
The industry began to transition as whole to 4Kn around 2010.
Because hard drives have gotten bigger and bigger, and each sector on a drive has additional overhead for storage and performance, 512B just didn't make sense anymore.
More information here:
What about ashift?
ashift is a zfs parameter that corresponds to sectorsize.
ashift is per-vdev and cannot be changed.
Using the same ashift across the pool is best practice, if for no other reason than just to avoid confusion.
The only values you are likely to ever need to choose between are 9 (for 512b drives) and 12 (for 4Kn drives)
What happens if I set my ashift...
Too low:
Setting this value to 9 when you have all 4Kn drives will cripple your pool performance horribly, as it will cause crazy write amplification. Every time ZFS wants to read or write a sector it has to read 4KB of data, modify 512B of it, and then write the whole 4KB back. It takes eight times as many operations to write 4KB of data.
Too High:
Setting this to 12 has no downsides unless all your drives are 512B.
4KB becomes the minimum size for all data, so anything smaller than that suffers from write amplification. (But if you have 4Kn drives, this is already the case.)
If you happen to know you have all 512Bn drives and you have no intention of ever adding any 4Kn drives, go ahead and use ashift 9.
If you have 512e drives, I recommend attempting a low-level format to convert them to 4Kn instead of using ashift=9.
For the other 99.999% of scenarios, the default value of 12 is correct.
If you have, or ever intend to have, even a single 4Kn drive in your pool at any point, set your ashift to 12. The tiny performance loss you'll see from using a value of 12 on 512B drives is not even worth talking about.
Oh, and in case you are wondering where the ashift numbers come from:
- 2^9 = 512
- 2^12 = 4096
ZFS vs RAID Controllers
ZFS does NOT play nicely with RAID controllers. Why? Because they do the same job, except ZFS is better at it.
A RAID controller manages the distribution of data across a pool of drives, warns you if a drive fails, and performs the resilvering process when you replace a drive. They often have their own cache, and bypass the cache of any drives connected. They also often have a battery, providing a quasi-substitute for PLP in SSDs (Which we will get to shortly).
Unfortunately RAID implementations are hardware-specific. If you set up a RAID and your RAID controller dies, you probably need to replace it with exactly the same RAID card for it to work.
This is why, in my homelab, I stay away from proprietary NAS like Synology, and those external USB RAID enclosures, and instead roll my own with a mini-PC and a DAS (Which is an enclosure that does not do any kind of RAID stuff, it just connects the disks.)
With ZFS, you can connect a pool to any computer with an OS that supports ZFS, and import the pool. Done.
But how do I connect my drives?
With a PCIe RAID controller. (If you're using a big boy computer.)
What?
I'm kidding. But not really.
The PCIe cards you use to connect SAS drives to a server or computer are called HBAs (Host-Bus Adapters). They often utilize these squid cables to allow you to connect multiple drives at once:

You'll probably want some kind of an HBA, but since most of them have RAID features enabled that will interfere with ZFS, you'll need to set it to Passthrough mode (aka IT Mode). This will (usually) disable the RAID cache management and other features, and simply present the disks to the system as-is. That will let ZFS do its work without interference.
Some HBAs allow this as a setting in the boot menu. Others require special firmware. If you are able to change the settings, and select Passthrough mode (it may be called Plain mode, or something else similar) it may work just fine with ZFS, or it may continue to use the cache on the card silently without telling you and screw everything up.
In that case, you'll want to look for "IT Mode Firmware" for that card, and flash it. There are IT mode firmwares for almost all the popular HBAs, and it's not terribly difficult to do, but if you're feeling overwhelmed you can also buy them pre-configured on ebay for pretty cheap.
Recently at work I dealt with a card that had no options for passthrough AND did not have an IT mode firmware available. We ended up having to replace it completely.
One bonus of using an HBA in your homelab; If you buy the right cables, you can use SAS drives as well as SATA, and used SAS drives are often significantly cheaper!
ZFS does not like USB
Just about all USB storage adapters, converters, enclosures, etc, present the storage within them to the system as a generic block device. The system throws the data at the block device having no idea what kind of drive is in there, and the hardware in the adapter manages sending it to the right place. It's actually quite similar to how hardware RAID works, (and in the case of RAID enclosures, that's exactly what's happening). This gets in the way of ZFS, because both things are doing the same job (except ZFS is much better at it). ZFS really needs low-level access to the disks to be able to manage where data is going and when, otherwise, even if it does work, it'll likely perform poorly.
USB devices are meant to be plug-and-play. They are designed to be connected and disconnected randomly without bad things happening. ZFS is NOT designed for drives to disconnect randomly, and will be very upset if that happens.
A lot of USB controllers built-in to motherboards are complete crap. A lot of USB enclosures are complete crap. A lot of USB cables are complete crap. A lot of external hard drives are complete crap. You get the idea.
If you're feeling dangerous, you can use something like I do at home; A USB DAS (Direct Attached Storage) connects the drives somewhat transparently to the system, and doesn't do any kind of caching or RAID. Please note this is a completely unsupported configuration. My configuration has been rock-solid, but I did have issues with other hardware. Namely a six-bay DAS from TERRAMASTER did not work well at all with ZFS and randomly disconnected individual drives, while a four-bay from the exact same company (and even the same product line) worked perfectly fine.
All about Drives
Hard drive
...is kind of a ubiquitous term, but it really means a form of non-volatile data storage (the kind that retains data when you turn off the power) that is made up of a few metal disks (Platters) rotating very quickly, and a few arms with tiny heads that zoom around the disks reading and writing data in the form of tiny magnetic dots.
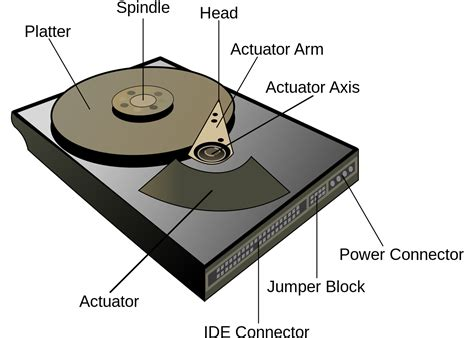
Cons of HDDS:
- These are kind of slow, because in order to fetch data the arm has to literally move across the disk AND wait for the disk to spin around to where the data is.
- They also use a lot of power because they have a motor spinning the platters and another motor driving the arm.
- They are fragile. Drop one while it's powered off, and you're probably ok. Drop one while it's still spinning and you are boned.
Pros of HDDs:
- Cheap. Per GB, HDDs (especially used) are among the best deal you can possibly get in any storage medium.
- Max capacity: You and I and any other joe schmoe can buy, right now, a single SATA hard drive with a 30TB capacity for a reasonable price.
- Long-term storage: HDDs tend to hold data well when disconnected and stored offline for long periods.
A solid state drive
is a permanent storage drive that uses flash memory, like a flash drive or SD card.

Pros of SSDs:
- Durable, as they have no moving parts at all.
- Fast, like crazy fast. Like your average HDD is maybe 200MB/s max. A cheap SSD is easily 10x that.
- Multiple form factors & interfaces. HDDs basically only exist as SATA or SAS, and in 3.5" or 2.5" format. SSD's are common in the 2.5", m.2 (in multiple lengths), and u.2 (pretty much enterprise only) form factors and with SATA or nvme interfaces (m.2 supports both).
- Much more power efficient, as they have no moving parts at all. The only power loss is heat, and that does vary depending on make & model.
Cons of SSDs:
- Expensive. A quick search on Amazon shows cheaper 4TB SSDs in the ~$200 range. A 4TB HDD can often be had for free, as that's fairly small for an HDD, but brand new you'd probably spend a bit over $50. (I've bought them used on ebay for $20) That's somewhere between a 4-10x difference, and it gets worse the higher you go in capacity.
- SSDs do not generally retain data as well in cold-storage situations as hard drives do. Flash memory stores data as an electric charge, which is more succeptible to environmental factors and likely won't last as long when disconnected as an HDD will.
- Multiple form factors; I know I said this was a Pro, but it can get confusing. Two m.2 drives that look nearly identical, one that is nvme and the other SATA, can have drastic performance differences. An m.2 slot may only support SATA, while a drive only supports nvme (many support both) so though it fits in the slot, it doesn't register in the OS.
- Data Density; 3.5" hard drives are standard, 3.5" SSDs basically don't exist. Flash memory just doesn't need as much space. If you have the machine to read the drives, you can theoretically fit WAY more flash storage in a given space than you could HDDs. Even 2.5" SSDs barely use any of the space in their case most of the time, look:

m.2 drives come in capacities up to 8TB and they're about the size of a stick of gum:

What about drive failure?
Drives fail. It happens. Drives fail in what's known as a bathtub curve. Here's an example:
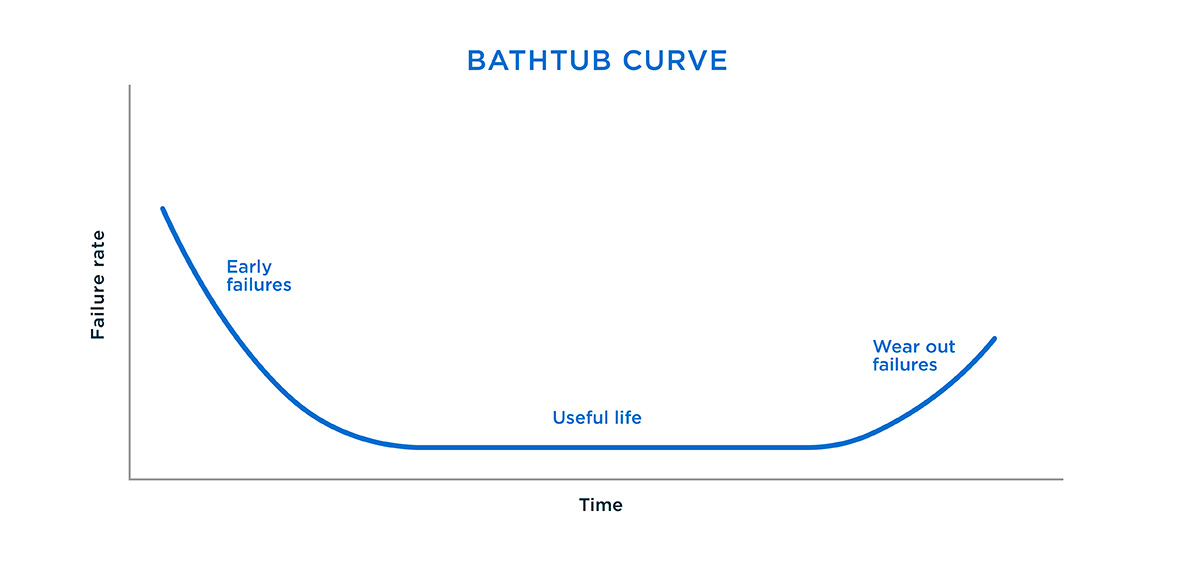
What this means is, the most likely time for your drive to fail is shortly after you buy it (assuming it is brand new.) Then the likelihood slowly drops off, to very, very low. Then as the drive wears out, that number climbs again.
This is why, for personal use, I recommend used, or refurbished drives. They have, in effect, already been vetted. They're significantly cheaper, they are past the initial "Early failures" stage, and they're actually a safer bet most of the time than new drives. HOWEVER they often do not have warranties (although refurbs bought from authorized sellers often do) and you don't really know how much of the "useful life" part you have left before hitting the "Wear out failures" part.
For personal use, I generally buy the cheapest used/refurbished drives per/TB that I can find on ebay, then I test them and configure them in a pretty robust ZFS mirror. Then I make sure I have backups. Though two drives arrived DOA once, I was able to return them, and aside from that, in the 15ish years I've been running a homelab I have never had a used drive fail on me. I have however, had a few Western Digital drives that I bought new fail after a few years. Many have had similar experiences, but there are those who disagree. In a work or enterprise environment, buy new or at least refurbished by the manufacturer, with a nice long warranty. The last thing you want is data loss without someone to scream at.
What about S.M.A.R.T.?
Basically all drives store and report what's known as SMART data (Self-Monitoring Analysis and Reporting Technology).
This tells you a bunch of different metrics about the drive, such as:
- How many times a drive has been powered on and off
- How long a drive has been powered on
- How many times an HDD has been spun up
- How many times an HDD has failed to spin up
There are a ton of different apps you can use to view SMART data from a drive connected to your machine, however whether or not this data actually helps you predict when a drive will fail is heavily debated and there doesn't seem to be a clear answer.
There are some SMART attributes that DEFINITELY indicate there is a serious problem, but often times drives just fail out of the blue with no warning signs at all.
Backblaze works with a LOT of drives (seeing as they are a massive cloud storage provider) and according to their data, in 2016 in 76.7% of HDD failures, one or more of the attributes below had a raw value greater than zero:

Having said that, many of the reporting metrics are cumulative over the life of the drive. Some drives may have a single reallocated sector near the beginning of their life and be fine for a decade.
More info on error distribution here.
Furthermore, not all drives report all metrics (most do not) and many don't even report in the same format (percentage vs count, etc.) If you have an external drive, or a drive connected to a USB enclosure, SMART data may not be accessible at all!
To complicate things further this data can be actually be wiped & reset! In fact usually when buying a refurbished drive, checking the SMART values will often show power-on-hours of zero. It isn't common, but some shady sellers have been caught resetting SMART data on used drives to cover up problems, or selling refurbished & reset drives as new.
Basically, with S.M.A.R.T.
- If you buy a new drive, check the SMART data and return it if it's been used.
- If you buy a used drive, check the SMART data and return it if it's been reset or there's anything horrifying in there.
- If you buy a refurbished drive, you can probably expect the data to be reset. If it isn't, and there's anything horrifying in there, return it.
Are SSDs or HDDs more durable?
Depends. I'd say the answer nowadays, all other things aside, is probably SSDs. They have no moving parts, and they don't really need any special treatment. You may have heard the term write endurance thrown around; SSDs technically wear out from being written to over and over again. With early SSD technology, and with cheap SSDs, this can be an issue as heavy use can wear them out prematurely. With any modern decent quality SSD, you could write Terabytes of data every day for years and they would continue working. The exception, as I mentioned before, is offline cold storage (like in a safe). An HDD, in an antistatic bag, with some silica beads to absorb moisture is a better bet for that.
How do I get the cheapest storage possible?
If you're in an enterprise or work environment, don't be stupid. Follow the rules. Get good storage with a warranty.
For the homelabbers:
- Buy used drives.
- SAS drives are usually significantly cheaper ($20 for a 4TB SAS drive vs $35 for a 4TB SATA) and much more resilient as they are enterprise-grade.
- If you are using a USB enclosure for your drives (even though it's a bad idea) there's a 99% chance you are stuck using SATA drives.
- If you have a spare PCIe slot you can pick up an HBA (Host-Bus Adapter) in IT Mode for less than $50 that will allow you (with the right cables) to connect eight or even sixteen SAS or SATA drives. You will need a way to power them though, and a place to hold them, even if it's just a shelf.
I will let you in on a secret...
diskprices.com
This website pulls listings from Amazon, and lets you sort by $/TB and filter by form factor and medium.
But if you really want to save money, I have an even better trick.
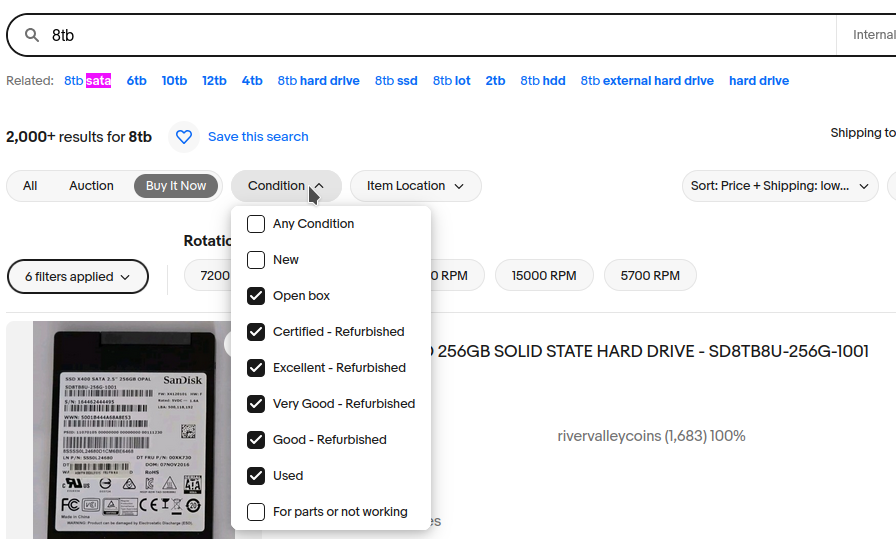
- Go to ebay.com
- Search for the desired capacity (e.g. "4TB") and nothing else.
- Under "Condition" Select "Open Box", "Certified - Refurbished", and "Used"
- Filter for "Buy it Now" listings only
- Click the "See more results" link at the top of the results.
- Sort by Price+Shipping, lowest first.
- Scroll all the way to the bottom, and change "Items per page" to as high as it will go. (Probably 240)
- Searching for just "4TB" eliminates a ton of random crap that would clog up the results.
- Filtering out the brand new products and only looking at used stuff removes all the Aliexpress drop-seller crap you'd normally see.
- Choosing "Buy it now" only eliminates all the irrelevant auctions where the price hasn't gone up yet.
- Choosing "See more results" shows you all the stuff ebay tries to hide from you because it considers it redundant, which often includes the thing you actually want.
Better yet, here's a link that does all of that for you.
Now, let's say we want a SATA drive. Don't search for "SATA 4TB", because that will show a bunch of stuff matching "SATA" of random capacities and purposes. Likewise, don't check the "SATA" box under "interface" on the left. Instead, press CTRL+F (Or do "find in page" on mobile) and search the page for "SATA". The things higher up on the page are likely to be garbage, you'll also have to ignore the "$23.99 to $32.99" price range things (that I absolutely HATE and don't belong here.) hit next until you see something promising.
Right now a 4TB SATA drive, used, can be had for about $35 shipped.
Often sellers list as "or Best Offer" and will knock a few dollars off if you ask, especially if you buy in bulk.
The cheapest 4TB 3.5" SATA drive on diskprices.com is also used, but it's $50. Often times the price difference is even more. I have paid, on average, $5/TB for my drives for many years now. At that price, you can afford to buy a few spares in case any fail.
To change capacities, don't search for the new capacity or you'll have to repeat most of the process of filtering and sorting. Instead, click the URL bar in your browser, find where it says "4TB" change it to "8TB" and click enter.

Also, check multiple capacities. Often times higher capacity drives are actually cheaper than lower capacity ones. When I bought my 6TB drives, the cheapest 4TB were about $5 more.
What about drive cache?
On hard drives, don't even look at cache amount.
In fact, if you're making a pool of 4 or more disks, I wouldn't even bother checking Read/Write speed or IOPS for HDDs. They all perform very similarly and price/capacity ratio is much more important.
For SSDs, do NOT ever buy a cacheless/non-cached/DRAM-less SSD.
The prices have mostly evened out between drives with cache and those without, and the performance and durability you'll get from having a drive cache is worth the couple dollars you might save.
If you already have a cacheless SSD...
They're fine. Maybe use it as a boot drive, or plop it in a cheap enclosure and use it like a flash drive or something. Just make sure you have backups, and definitely don't use DRAM-less SSDs with ZFS. That is asking for a bad time.
Do I need PLP?
Remember how I said cutting the power when there's data pending in your drive's cache can cause data loss? That is true, unless you have SSDs and your SSDs have a thing called PLP (Power Loss Protection)
PLP is basically a little capacitor built into the drives that, in the event of a power outage, gives them just enough juice to finish writing the cache to FLASH memory before turning off.
- Most consumer SSDs do not have PLP.
- Most enterprise-grade SSDs do.
TL;DR If you really care about your data, use drives with PLP
There is no real PLP alternative for HDDs, and things are a bit more complicated here, as hard drives write in a stream of data and can therefore write a partial sector, whereas SSDS literally "Flash" a whole sector with data at once.
Additionally, some hard drives seem to report back to the system as soon as they have the data in their cache. Others do not report back until the data has actually been written. This doesn't get talked about nearly enough, because in practice the conditions where this would cause issues are rare.
On the bright side...
There is an alternative to PLP that I think is underdiscussed and underutilized:
What if the entire server had a battery that would keep it running for a while if the power failed, instead of just the drives?
Does such a device exist? Yes!
The Uninterruptable Power Supply (UPS)
For home use, buy a UPS on Amazon, (They even have AmazonBasics brand UPS' now) and plug your home server and drive enclosure into that. It will do you a heck of a lot more good than PLP will.
So how am I supposed to configure my pool?
Generally speaking, the more vdevs, the better. That means making each vdev as small as possible. That's a good place to start.
While all the rules for pools hold true at scale, if you're in a homelab environment with just a handful of drives, things can get squirrely.
What RAID level do I need?
Mirrors
Upsides:
- Excellent redundancy/safety (50%)
- Excellent read speeds (Single Drive Speed x Number of Drives)
- Smaller vdevs = more vdevs = faster real-world write speed than RAIDz
- Trivial to resilver. if a disk fails.
Downsides:
- Lowest storage capacity of all the options (50%)
- Writes are not as fast as a stripe.
- Slower write speed than fantasy-world RAIDz options.
In my humble opinion, If you can afford to give up half the storage, a pool of 2-drive-wide mirrors is the way to go. I use mirror vdevs almost exclusively at home and at work.
-
Real-world read performance matches a stripe
-
Real-world writes are very good with more than one vdev
-
They have plenty of redundancy
-
If you have a small number of drives (Say 6 or 8) you can still get a decent number of vdevs in there to speed things up.
-
The resilvering speed is really underrated. It sucks having to replace a drive and wait hours to rebuild in a mirror. What's worse is replacing a drive in a RAIDz, waiting days for it to rebuild, and praying another drive doesn't fail in the meantime.
Choose striped vdevs if:
- You literally do not care about whether the data randomly disappears or not.
OR - You DO care about the data, but absolutely MUST squeeze every single bit of storage out and you are making regular backups elsewhere
OR - You DO care about the data, but absolutely MUST squeeze every single bit of speed out and you are making regular backups elsewhere
OR - You are a masochist who enjoys suffering.
Choose RAIDz if:
- You need more storage than a mirror would give you.
- AND
- You still want some kind of redundancy in case of failure.
Do I need encryption?
Yes. Just do it. Unless you are running a CPU older than Skylake (Intel 6th Generation) without the AES-NI instruction set, you aren't going to notice a performance difference, and you'll sleep a little safer at night.
Do I need compression?
Yes. Turn it on. Leave it on. Leave it to the default compression algorithm (LZ4) if you don't want to fiddle with things.
99.99999999% of the time, it's the right choice and your pool will be faster as a result.
If you really need the space, and you have a lot of very compressible data (Think documents, not Movies & Music) then play around by making a few datasets with different compression levels/algorithms, copying an identical copy of a representative sampling of your data over to each one, and checking the compression ratio.
Alternatively, (and others will disagree, but they are incorrect) if you have a ton of CPU power to spare, your data doesn't change all that much, and you've got nothing to lose, crank that compression up to ZSTD-19 or something and go for it. (Please verify that whatever algorithm you choose actually does a better job than LZ4 though. Depending on the data, that may not be the case.)
Do I need deduplication?
No.
ZFS deduplication is much MUCH better now than it used to be (and how the internet still seems to believe it is) but it's still pointless for all but a very small subset of scenarios that you, or I, or anyone else are very unlikely to encounter, even in an enterprise scenario. If you do end up needing it later on, remember, it works at the dataset level, so you can always create a new dataset, enable deduplication, and move your crap over.
What about backups?
If you decided you need RAID, you probably also need backups.
Imagine you lost all the data on your pool. How screwed are you?
The classic 3-2-1 backup strategy is as follows:
- 3 backups total
- 2 backups on different media types
- 1 backup off-site.
I don't love this strategy. I believe it is flawed in a number of ways.
There are only a handful of realistic threats to your data:
- Drive Failure - One or more drives have failed, but not the pool.
- Data Corruption - Some portion of the data has been obliterated.
- Complete Pool Failure - Drives are toast, All the data on the pool is gone.
- Complete Server Failure - Server is toast, drives are toast, All the data on all the pools on the server is gone.
- Natural Disaster/Theft
- Ransomware/Hacking
When coming up with ideas for a safe multi-tiered backup approach, ask yourself these questions:
Is this backup on the same storage/drives?
- Examples would be RAID or ZFS Snapshots. This does protect from corruption and hardware failure to a certain extent, but if the storage fails completely all your data is gone.
Is this backup on the same server or machine?
- Assuming the backup is not stored on the same drives, is it on the same server? An example would be a USB enclosure connected to your server that holds backups for the main storage. This protects against failure of the pool completely, but if the server gets toasted by a power spike, you may lose your backups as well.
Is this backup in the same physical location?
- This would be things like a second server in your garage, or an external hard drive you back up to once a week and store in your dresser. This protects against complete server failure, but not natural disaster or theft/robbery.
These three questions will tell you, more or less, to which of the threats your backups are resistant. That doesn't mean that every solution that checks these boxes will be a good one however:
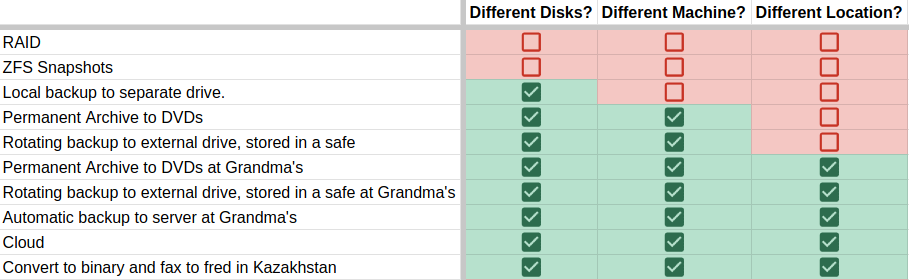
So obviously we need to ask a few more questions here.
These are questions of convenience more than safety.
Two that come to mind immediately are
- How quick/easy is it to restore the data?
- Is there any recurring cost (beyond electricity?)
These are both relevant and should definitely be factored in, however the big boy question that I believe does NOT get asked nearly enough:
Can you automate it?
If you can't automate the backups, what's the likelihood of you actually doing it? What's the chance that when a big whatever does happen, you'll have a backup recent enough to be worth bothering with?
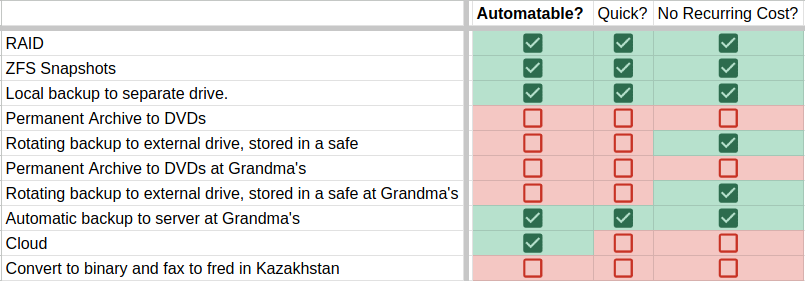
Note: I consider DVDs to have a recurring cost, albeit a small one, as they are WORM storage (Write-Once, Read-Many) and thus as you add data you must buy more DVDs.
There is an exception to the automation question, and that's for data that isn't ever modified, nor is any new data ever added, like a permanent archive. For that kind of data, it's perfectly fine to throw it on a DVD or External HDD and leave it in a safe. Most of the time there will be at least some data that needs to be added once in a while, and if that's the case, you are far better off going with one of the automatable options.
You'll also notice I have not mentioned media types.
In my opinion, media types really only matter for cold storage, meaning storage that is not immediately live & accessible, like DVDs or Hard Drives in a safe. If the ONLY place you have your data stored is on an external hard drive in a safe, it's probably a good idea to also have another copy on DVDs if possible as each storage medium is succeptible to failure under a different set of conditions. For example, if there's an environmental problem like humidity or a flood that ruins the HDD, the DVDs may be just fine.
For hot storage
...like the pool attached to your server, the other factors matter so much more that medium type becomes completely irrelevant. Could humidity destroy the drives in your pool, AND the drives in the pool in the server at Grandma's house simultaneously? Technically, yes, but is that more likely than a power spike ruining your server, or your house being destroyed in a fire or robbed? Probably not. Is it worth backing up all your terabytes of "linux ISOs" onto DVDs? Only if you enjoy pain and suffering.
Having said all that, which options from our examples are the most resilient?
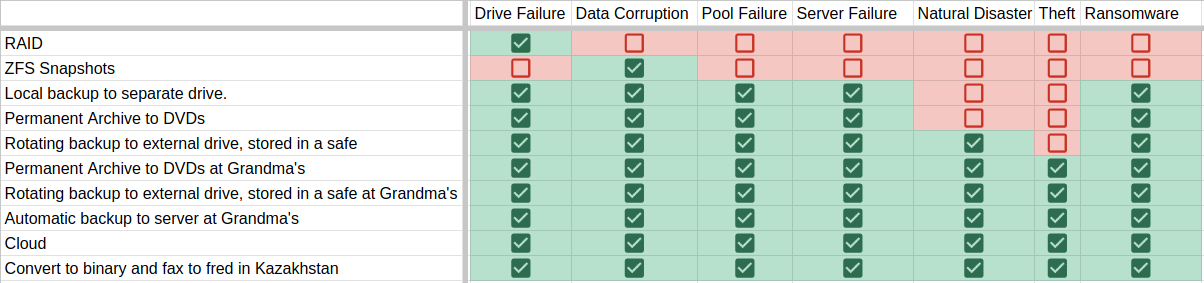
Well, a server at grandma's is looking like a pretty good option...
That's because it is.
We've marked Server at Grandma's as being resistant to natural disaster, and that's true. For safety purposes, the further away grandma's house is, the better. A hurricane could still technically take out both of your houses.
But what if the server at Grandma's fails?
Well, that's where the convenience aspect comes in. Is your server an old piece of crap? Does Grandma's house still have knob-and-tube wiring from the 1920's? Does she live in a different country known for their violent hostility towards people whose Grandmas are still around?
Cloud backups are awesome,
but they are not free if you want any storage beyond 100GB or so. They are also slow as balls to backup and even slower to restore. BUT they can be automated, and keeping the servers alive is someone else's problem, so cloud storage is awesome in enterprise environments (as a plan C).
There's also the matter of upfront cost.
Even for the options that have no recurring cost, you'll need to make some kind of initial investment. RAID assumes you have the extra storage for parity, as do ZFS snapshots. You'll need an external drive to toss in a safe, or a whole other computer with drives and a way to connect them (like an enclosure) if you want a server at grandma's. This is hard to quantify as you likely have some crap lying around you can use. Even at work, I've repurposed old servers and drives for backups many, many times.
Miscellaneous Questions
Can I mix data vdev types in a single pool?
Yes. Don't. Remember, if any vdev fails completely, your entire pool is lost. Your pool is therefore only as reliable as your lowest-parity vdev. This isn't even an option within the TrueNAS UI, and for good reason. If you have 5 drives for example, consider making a 2x2 mirror with a single hotspare instead of one RAIDz1 and one mirror.
Can I use a single vdev in a pool?
Yes! Although generally unless you have very few disks, that's not the best idea from a performance perspective. If you have, for example, a 5 disk array and you choose to go with RAIDz2, you're going to have a single vdev.
Also if you're using stripe vdevs, there shouldn't be much difference in the number or width of vdevs.
Is it true that performance is better with an even number or some specific number of disks?
Not really. There is a common misconception that the best performance comes from using a number of disks that's equal to
(some power of 2 + number of parity disks)
e.g:
- RAIDz1 = (2^1 disks + 1 parity disk) = 3 disks
- RAIDz2 = (2^2 disks + 2 parity disks) = 6 disks
- RAIDz3 = (2^2 disks + 3 parity disks) = 7 disks
This has been debunked by the guy who's pretty much the head ZFS dev.
You can take a look here, scroll down the "Common Misconceptions" portion.
This assumption was based off the fact that most data written to your pool will have a blocksize that's a power of 2 (4k, 8k, and 32k are common) and those blocksizes are easier to split up between a set of drives that's also a factor of two. ZFS compression throws that out the window, because ZFS we end up with blocks that are random size depending on how much ZFS was able to compress them. The performance benefits of compression outweigh any performance cost from the square-rootness of the vdev by a wide margin, so it's a non-issue.
Why do you recommend minimum numbers of disks for RAIDz?
Because MATH!
A mirror has at LEAST 50% redundancy, and because they perform so much better than RAIDz, if you're going to go to (or past) the 50% redundancy mark, you should just switch to mirrors. (Going past 50% is pretty uncommon anyway.)
Some examples:
- RAIDz1 with 3 drives has (1 Parity/3 Total) 33% redundancy
- RAIDz1 with 2 drives has (1 Parity/2 Total) 50% redundancy
- RAIDz2 with 5 drives has (2 Parity/5 Total) 40% redundancy
- RAIDz2 with 4 drives has (2 Parity/4 Total) 50% redundancy
- RAIDz3 with 7 drives has (3 Parity/7 Total) 42.8% redundancy
- RAIDz3 with 6 drives has (3 parity/6 total) 50% redundancy
The recommended numbers for each RAID level are the fewest you can have in one vdev without crossing the 50% mark where mirrors make more sense.
Can I add a vdev to a pool later on?
Yes you can, and it will increase the capacity of the pool accordingly, and NEW data will be split between the old vdevs and the new ones... However OLD data will NOT be automatically redistributed. This means, if your pool had two identical vdevs when you created it, and your pool has 500GB of data on it, each vdev has 250GB of data on it. If you add a third vdev, ZFS does NOT automatically split the data up and add a portion to the new vdev. However, new data written WILL be divided three ways, with a bigger portion sent to the emptier drive, so it will balance itself out eventually.
How do I redistribute/reallocate data after adding a new vdev?
There is an ongoing push in the dev community to get a feature added into ZFS that does just this, but for now the only way is either to move all the data off the pool then move it back, or to create a copy on the same pool and delete the old data.
Create an Encryption Key
First, we'll generate a 32-byte random key file.
Run the below command, and feel free to change /KEYFILE.key to whatever you like.
Make a backup of this key and store it somewhere safe.
dd if=/dev/urandom bs=32 count=1 of=/KEYFILE.key
Create a ZFS Pool
The zpool create command has flags for both pool properties (-o) and filesystem properties (-O). Whose idea was it to make them so ambiguous? I don't know, but it's the source of headaches for many online. Just mind the case.
Here's an example of a typical command I use to create a ZFS Mirror
zpool create -o feature@encryption=enabled -O encryption=on -O keyformat=raw -O keylocation=file:///KEYFILE.key -O compression=on -m /MOUNT_DIR POOL_NAME mirror /dev/SD? /dev/SD?
What's going on here?
Well, a number of things...
We are enabling encryption on the root dataset. By default this setting will trickle down to any other datasets we create.
-o feature@encryption=enabled
Then we're setting a number of default filesystem options:
We're setting encryption to "on", although we could choose a specific algorithm if we wanted.
-O encryption=on
We're setting the keyformat to "raw" meaning we'll be providing a keyfile instead of a password. We can change this option to "passphrase" if we like.
-O keyformat=raw
We're specifying the location of the keyfile for decryption.
-O keylocation=file:///KEYFILE.key
We're specifying that we want compression enabled. There are a number of algorithms we could specify. By default this uses the lz4 algorithm which is very efficient and generally improves i/o throughput.
-O compression=on
We're specifying where we want the root dataset mounted.
-m /MOUNT_DIR
We're giving the pool a name.
POOL_NAME
We're setting the pool to mirror mode (RAID10)
mirror
We're giving two devices to mirror. (We'll add more later)
/dev/SD? /dev/SD?



